中文分词,通俗来说,就是将一句(段)话按一定的规则(算法)拆分成词语、成语、单个文字。
中文分词是很多应用技术的前置技术,如搜索引擎、机器翻译、词性标注、相似度分析等,都是先对文本信息分词处理,再用分词结果来搜索、翻译、对比等。
在Python中,最好用的中文分词库是jieba。用“结巴”给一个中文分词库命名,非常生动形象,同时还带有一种程序员式的幽默感。
最好的Python中文分词组件
“结巴”中文分词:做最好的Python中文分词组件
这是jieba分词的slogan,打开jieba分词的GitHub、PyPI源,都会在简介里看到这句标语。这充分体现了jieba开发团队的愿景和目标,在目前看来,jieba已经称得上最好的Python中文分词库。
2022年4月写本文时,jieba在GitHub上已经获得了28.3K的Star,而且数量正在快速增长,足够证明jieba的受欢迎程度非常高。
jieba除了有Python语言的版本,也有C++、JAVA、iOS等十几门编程语言的版本,从PC端到移动端,都可以支持。这点值得给jieba的维护团队点赞,说不定未来,jieba可以做所有语言里最好的中文分词组件。
jieba的使用方法
Step1. 安装jieba
pip install jieba
jieba是第三方库,需要先安装才能使用,直接使用pip安装即可,jieba兼容Python2和Python3,安装命令都一样。如果安装慢,可以添加-i参数指定镜像源。
Step2. 调用jieba进行分词
import jieba
test_content = '迅雷不及掩耳盗铃儿响叮当仁不让世界充满爱之势'
cut_res = jieba.cut(test_content, cut_all=True)
print(list(cut_res))
运行结果:
['迅雷', '迅雷不及', '迅雷不及掩耳', '不及', '掩耳', '掩耳盗铃',
'儿', '响叮当', '叮当', '当仁不让', '不让', '世界', '充满', '爱',
'之', '势']
jieba分词的使用非常简单,直接导入jieba库,调用cut()方法,传入需要切分的内容,即可返回分词结果。返回结果是一个可迭代的生成器generator,可以进行遍历,也可以转换成list打印出结果。
jieba分词的四种模式
jieba分词支持四种分词模式:
1.精确模式
试图将句子最精确地切开,适合文本分析。
cut_res = jieba.cut(test_content, cut_all=False)
print('[精确模式]:', list(cut_res))
cut_res = jieba.cut(test_content, cut_all=False, HMM=False)
print('[精确模式]:', list(cut_res))
[精确模式]: ['迅雷不及', '掩耳盗铃', '儿响', '叮', '当仁不让',
'世界', '充满', '爱之势']
[精确模式]: ['迅雷不及', '掩耳盗铃', '儿', '响', '叮', '当仁不让',
'世界', '充满', '爱', '之', '势']
精确模式是最常用的分词模式,分词结果不存在冗余数据。
HMM参数默认为True,根据HMM模型(隐马尔可夫模型)自动识别新词。如上面的例子中,HMM为True,结果中将“儿响”、“爱之势”识别成了新词,HMM为False,这些字只能单独成词,分成单个文字。
2.全模式
把句子中所有可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
cut_res = jieba.cut(test_content, cut_all=True)
print('[全模式]:', list(cut_res))
[全模式]: ['迅雷', '迅雷不及', '迅雷不及掩耳', '不及', '掩耳', '掩耳盗铃',
'儿', '响叮当', '叮当', '当仁不让', '不让', '世界', '充满', '爱', '之', '势']
全模式从待分词内容的第一个字开始遍历,将每一个字作为词语的第一个字,返回所有可能的词语,会重复利用词语和字,因此也可能会出现多种含义。
cut_all参数默认为False,即默认不是全模式,将cut_all设置为True,则采用全模式分词。
3.搜索引擎模式
在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
cut_res = jieba.cut_for_search(test_content)
print('[搜索引擎模式]:', list(cut_res))
[搜索引擎模式]: ['迅雷', '不及', '迅雷不及', '掩耳', '掩耳盗铃', '儿响',
'叮', '不让', '当仁不让', '世界', '充满', '爱之势']
搜索引擎模式在精确模式的基础上,对精确模式中的长词,再按照全模式进一步分词,用于搜索时可以匹配到更多的结果。
4.paddle模式
利用PaddlePaddle深度学习框架jieba库,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
paddle模式使用需先安装paddlepaddle-tiny创业项目,安装命令:pip install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba v0.40以下版本,请升级jieba,pip install jieba –upgrade 。
上面是官方的描述,但是,当前已经找不到paddlepaddle-tiny镜像源了,感兴趣可以去PaddlePaddle官网找找方法。
通常不会使用到paddle模式jieba库,所以我们了解前面三种模式即可。
5.小结
cut()方法有四个参数,sentence接收待分词的内容;cut_all设置是否使用全模式;HMM设置是否使用HMM模型识别新词;use_paddle设置是否使用panddle模式。
cut_for_search()有两个参数,sentence和HMM。
cut()和cut_for_search()都是返回generator,如果想直接返回列表,可以使用对应的lcut()和lcut_for_search(),用法完全相同。
自定义分词词典
使用jieba分词时,分词结果需要与jieba的词典库进行匹配,才能返回到分词结果中。因此有些词需要用户自定义,才能识别到。
1.添加自定义词语到词典中
jieba.add_word('铃儿响叮当')
jieba.add_word('让世界充满爱')
jieba.add_word('迅雷不及掩耳之势')
lcut_res = jieba.lcut(test_content, cut_all=True, HMM=False)
print('[添加自定义词语]:', lcut_res)
[添加自定义词语]: ['迅雷', '迅雷不及', '迅雷不及掩耳', '不及', '掩耳', '掩耳盗铃',
'铃儿响叮当', '响叮当', '叮当', '当仁不让', '不让', '让世界充满爱', '世界',
'充满', '爱', '之', '势']
add_word()有三个参数,分别是添加的词语、词频和词性,词频和词性可以省略。
添加自定义词语后,自定义词语如果能匹配到,就会返回到分词结果中。如果自定义词语在待分词语句中没有连续的匹配结果,分词结果中不会体现。
2.添加指定的文件作为分词词典
自定义词典格式要和默认词典dict.txt一样,一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name若为路径或二进制方式打开的文件,则文件必须为UTF-8编码。
本文自定义一个mydict.txt文本文件,内容如下:
迅雷不及掩耳之势 3 a
掩耳盗铃 3 a
铃儿响叮当 3 a
当仁不让 3 a
让世界充满爱 3 n
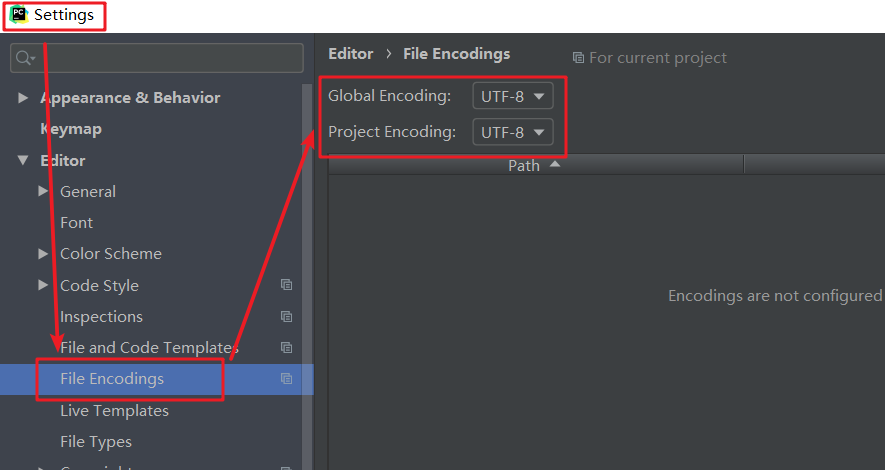
文件编码要设置成UTF-8,在PyCharm可以点击File>Settings>File Encodings,将Global Encoding和Project Encoding设置成UTF-8。
然后使用load_userdict()加载自定义词典。
jieba.load_userdict('mydict.txt')
lcut_res = jieba.lcut(test_content, cut_all=True, HMM=False)
print('[使用自定义词典]:', lcut_res)
[使用自定义词典]: ['迅雷', '迅雷不及', '迅雷不及掩耳', '不及', '掩耳', '掩耳盗铃',
'铃儿响叮当', '响叮当', '叮当', '当仁不让', '不让', '让世界充满爱', '世界',
'充满', '爱', '之', '势']
使用了自定义词典,会同时根据jieba的默认词典和自定义词典进行分词。添加自定义词典和添加单个词语的效果一样,区别是可以批量添加,而不用重复调用add_word()。
3.从词典中删除词语
jieba.del_word('不及')
jieba.del_word('不让')
jieba.del_word('之')
lcut_res = jieba.lcut(test_content, cut_all=True, HMM=False)
print('[删除词语]:', lcut_res)
[删除词语]: ['迅雷', '迅雷不及', '迅雷不及掩耳', '掩耳', '掩耳盗铃', '儿',
'响叮当', '叮当', '当仁不让', '世界', '充满', '爱', '之', '势']
删除的词语一般是语气助词、逻辑连接词等,这些词对于文本分析没有实际意义,反而会成为干扰。
在设置删除的词语后,结果中不再有删除的词语,但对于单个字,会独立成词,所以删除后在结果中也还存在。
4.调整词语的词频
调整词语的词频,调整其在结果中被分出来的可能性,使分词结果满足预期。分两种情况,一种是将分词结果中的一个长词拆分成多个词,另一种是将分词结果中的多个词组成一个词。
lcut_res = jieba.lcut(test_content, cut_all=False, HMM=False)
print('[设置前]:', lcut_res)
jieba.suggest_freq('让世界充满爱', True)
lcut_res = jieba.lcut(test_content, cut_all=False, HMM=False)
print('[设置后]:', lcut_res)
[设置前]: ['迅雷不及', '掩耳盗铃', '儿', '响', '叮', '当仁不让', '世界', '充满', '爱', '之', '势']
[设置后]: ['迅雷不及', '掩耳盗铃', '儿', '响叮当', '仁', '不', '让世界充满爱', '之', '势']
suggest_freq()有两个参数,segment参数表示分词的片段,如果是将一个词拆开,则传入拆开后的元组,如果是指定某个词要作为一个整体,则传入字符串;tune参数为True,则调整词语的词频。
注意:自动计算的词频在使用HMM新词发现功能时可能无效。
关键词提取
关键词提取使用jieba中的analyse模块,基于两种不同的算法,提供了两个不同的方法。
1.基于TF-IDF算法的关键词提取
from jieba import analyse
key_word = analyse.extract_tags(test_content, topK=3)
print('[key_word]:', list(key_word))
key_word = analyse.extract_tags(test_content, topK=3, withWeight=True)
print('[key_word]:', list(key_word))
[key_word]: ['迅雷不及', '儿响', '爱之势']
[key_word]: [('迅雷不及', 1.7078239289857142), ('儿响', 1.7078239289857142), ('爱之势', 1.7078239289857142)]
extract_tags()方法有四个参数,sentence为待提取的文本;topK为返回最大权重关键词的个数,默认值为20;withWeight表示是否返回权重,是的话返回(word, weight)的list,默认为False;allowPOS为筛选指定词性的词,默认为空,即不筛选。
2.基于TextRank算法的关键词提取
key_word = analyse.textrank(test_content, topK=3)
print('[key_word]:', list(key_word))
allow = ['ns', 'n', 'vn', 'v', 'a', 'm', 'c']
key_word = analyse.textrank(test_content, topK=3, allowPOS=allow)
print('[key_word]:', list(key_word))
[key_word]: ['儿响', '世界']
Prefix dict has been built successfully.
[key_word]: ['充满', '儿响', '世界']
textrank()方法与extract_tags()方法用法相似,需要注意的是allowPOS有默认值(‘ns’, ‘n’, ‘vn’, ‘v’),默认筛选这四种词性的词,可以自己设置。其他参数都与extract_tags()方法相同。
词性标注
词性标注使用jieba中的posseg模块,标注分词后每个词的词性,采用和ictclas兼容的标记法。
from jieba import posseg
pos_word = posseg.lcut(test_content)
print(pos_word)
[pair('迅雷不及', 'i'), pair('掩耳盗铃', 'i'), pair('儿响', 'n'),
pair('叮', 'v'), pair('当仁不让', 'i'), pair('世界', 'n'),
pair('充满', 'a'), pair('爱', 'v'), pair('之', 'u'), pair('势', 'ng')]
posseg.lcut()有两个参数,sentence和HMM。
词性和词性标签参考下表:
标签含义标签含义标签含义标签含义
普通名词
方位名词
处所名词
时间
nr
人名
ns
地名
nt
机构名
nw
作品名
nz
其他专名
普通动词
vd
动副词
vn
名动词
形容词
ad
副形词
an
名形词
副词
数量词
量词
代词
介词
连词
助词
xc
其他虚词
标点符号
PER
人名
LOC
地名
ORG
机构名
TIME
时间
返回词语在原文的起止位置
返回词语在原文的起止位置使用jieba中的Tokenize模块,实际调用时使用tokenize()方法。
res = jieba.tokenize(test_content)
for r in res:
if len(r[0]) > 3:
print('word:{}t start:{}t end:{}'.format(*r))
elif len(r[0]) > 1:
print('word:{}tt start:{}t end:{}'.format(*r))
else:
print('word:{}ttt start:{}t end:{}'.format(*r))
word:迅雷不及 start:0 end:4
word:掩耳盗铃 start:4 end:8
word:儿响 start:8 end:10
word:叮 start:10 end:11
word:当仁不让 start:11 end:15
word:世界 start:15 end:17
word:充满 start:17 end:19
word:爱之势 start:19 end:22
tokenize()方法有三个参数,unicode_sentence为待分词内容,注意,只接受unicode编码内容;mode参数为指定分词模式,如需要使用搜索引擎模式,则设置mode=’search’;HMM默认为True。
注册会员查看全部内容……
限时特惠本站每日持续更新海量各大内部创业教程,年会员只要98元,全站资源免费下载
点击查看详情
站长微信:9200327