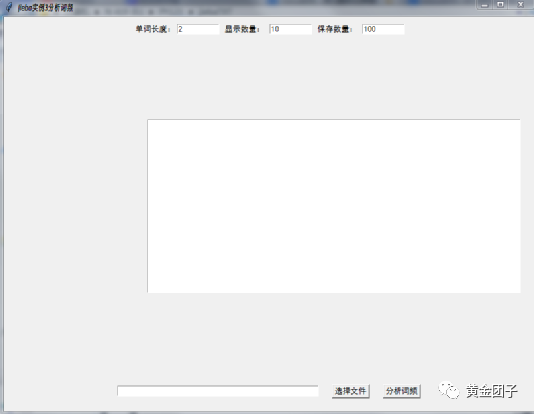
分享一个基于jieba库的Python 代码jieba库,它可以对文本进行分词和词频统计,并提供了图形界面。
代码效果是,选择文本文档分词并统计词频,显示并保存。
单词长度、显示数量、保存数量可以在界面选择。
▼代码注释
import tkinter as tkfrom tkinterimport filedialogimport jieba# 创建一个WordFrequenceAnalyzer类class WordFrequenceAnalyzer:def __init__(self):# 创建一个窗口实例self.window = tk.Tk()self.window.title("Jieba词频分析") # 设置窗口标题self.window.geometry("800x600") # 设置窗口大小# 创建顶部的Frame组件,放置单词长度、显示数量和保存数量的相关组件self.top_frame = tk.Frame(self.window)self.word_length_label = tk.Label(self.top_frame, text="单词长度:") # 单词长度的标签self.word_length_entry = tk.Entry(self.top_frame, width=10) # 单词长度的输入框self.word_length_entry.insert(0, "2") # 默认设置为2self.word_length_label.pack(side=tk.LEFT) # 放置在左侧self.word_length_entry.pack(side=tk.LEFT) # 放置在左侧self.topn_label = tk.Label(self.top_frame, text="显示数量:") # 显示数量的标签self.topn_entry = tk.Entry(self.top_frame, width=10) # 显示数量的输入框self.topn_entry.insert(0, "10") # 默认设置为10self.save_label = tk.Label(self.top_frame, text="保存数量:") # 保存数量的标签self.save_entry = tk.Entry(self.top_frame, width=10) # 保存数量的输入框self.save_entry.insert(0, "100") # 默认设置为100self.topn_label.pack(side=tk.LEFT, padx=5) # 放置在左侧,x轴的内间距5像素self.topn_entry.pack(side=tk.LEFT) # 放置在左侧self.save_label.pack(side=tk.LEFT, padx=5) # 放置在左侧,x轴的内间距5像素self.save_entry.pack(side=tk.LEFT) # 放置在左侧self.top_frame.pack(side=tk.TOP, padx=10, pady=10) # 放置在窗口顶部,x和y轴外间距为10像素# 创建底部的Frame组件,放置选择文件的按钮和分析词频的按钮self.bottom_frame = tk.Frame(self.window)self.filepath_entry = tk.Entry(self.bottom_frame, width=50) # 文件路径显示框self.browse_btn = tk.Button(self.bottom_frame, text="选择文件", command=self.load_file) # 选择文件的按钮self.filepath_entry.pack(side=tk.LEFT, padx=10, pady=10) # 放置在左侧,x和y轴的内间距为10像素self.browse_btn.pack(side=tk.LEFT, padx=10, pady=10) # 放置在左侧,x和y轴的内间距为10像素self.analyze_btn = tk.Button(self.bottom_frame, text="分析词频", command=self.analyze) # 分析词频的按钮self.analyze_btn.pack(side=tk.RIGHT, padx=10, pady=10) # 放置在右侧,x和y轴的内间距为10像素self.bottom_frame.pack(side=tk.BOTTOM, padx=10, pady=10) # 放置在窗口底部,x和y轴外间距为10像素# 创建右侧的Frame组件,放置词频分析结果的文本框self.right_frame = tk.Frame(self.window)self.result_text = tk.Text(self.right_frame, height=20) # 词频分析结果文本框self.result_text.pack(side=tk.TOP, padx=10, pady=10) # 放置在上方,x和y轴的内间距为10像素self.right_frame.pack(side=tk.RIGHT, padx=10, pady=10) # 放置在窗口右侧,x和y轴外间距为10像素self.window.mainloop()# 进入事件循环,运行窗口实例def load_file(self):filepath = tk.filedialog.askopenfilename()# 打开文件选择对话框,获取用户选择的文件路径self.filepath_entry.delete(0, tk.END)# 删除文件路径显示框中的旧内容self.filepath_entry.insert(0, filepath)# 将新的文件路径插入到文件路径显示框中def analyze(self):filepath = self.filepath_entry.get()# 获取文件路径显示框中的文件路径word_length = int(self.word_length_entry.get())# 获取单词长度输入框中的单词长度topn = int(self.topn_entry.get())# 获取显示数量输入框中的显示数量save_num = int(self.save_entry.get())# 获取保存数量输入框中的保存数量word_count = {}# 创建一个空字典,用于统计单词出现的次数with open(filepath, "r", encoding="utf-8") as f:# 打开文件并以utf-8编码读取内容for line in f:# 遍历文件的每一行words = jieba.cut(line.strip())# 使用jieba库对每一行进行分词处理for word in words: # 遍历分词结果if len(word) == word_length: # 如果单词的长度符合要求if word in word_count: # 如果单词已经在字典中word_count[word] += 1 # 将该单词的次数加1else: # 如果单词不在字典中word_count[word] = 1 # 将该单词的次数设置为1sorted_words = sorted(word_count.items(), key=lambda x: x[1], reverse=True)# 对单词按词频进行排序result_str = f"前{topn}个单词及其词频:n" # 初始化结果字符串for i, (word, freq) in enumerate(sorted_words[:topn]):# 遍历排序后的单词列表的前topn个单词及其词频result_str += f"{i+1}. {word}:{freq}n"# 将单词及其词频添加到结果字符串中self.result_text.delete(1.0, tk.END)# 清空词频分析结果文本框的内容self.result_text.insert(tk.END, result_str)# 将结果字符串插入到词频分析结果文本框中with open("jieba_词频.txt", "w", encoding="utf-8") as f:# 打开文件并以utf-8编码写入内容for i, (word, freq) in enumerate(sorted_words[:save_num]):# 遍历排序后的单词列表的前save_num个单词及其词频f.write(f"{i+1}. {word}:{freq}n")# 将单词及其词频写入文件中# 主函数def main():word_analyzer = WordFrequenceAnalyzer()# 创建一个WordFrequenceAnalyzer的实例if __name__ == '__main__':main() # 调用主函数运行程序#主函数def main():word_analyzer = WordFrequenceAnalyzer()# 创建一个WordFrequenceAnalyzer的实例if __name__ == '__main__':main()# 调用主函数运行程序
▼知识点
※tkinter模块:这是一个用于创建图形用户界面(GUI)的标准库,可以用来制作窗口、的按钮、文本框等组件
创建一个窗口(Window)对象,用来显示GUI程序的主界面。代码如下:
self.window = tk.Tk()self.window.title("Jieba实例3分析词频")self.window.geometry("800x600")
创建一个框架(Frame)对象创业项目,用来作为其他组件的容器。代码如下:
self.top_frame = tk.Frame(self.window)self.bottom_frame = tk.Frame(self.window)self.right_frame = tk.Frame(self.window)
创建一些标签(Label)对象,用来显示一些文本信息。代码如下:
self.word_length_label = tk.Label(self.top_frame, text="单词长度:")self.topn_label = tk.Label(self.top_frame, text="显示数量:")self.save_label = tk.Label(self.top_frame, text="保存数量:")
创建一些文本框(Entry)对象,用来获取用户输入的一些参数。代码如下:
self.word_length_entry = tk.Entry(self.top_frame, width=10)self.word_length_entry.insert(0, "2")self.topn_entry = tk.Entry(self.top_frame, width=10)self.topn_entry.insert(0, "10")self.save_entry = tk.Entry(self.top_frame, width=10)self.save_entry.insert(0, "100")
创建一个按钮(Button)对象,用来让用户选择要分析的文件。代码如下:
self.browse_btn = tk.Button(self.bottom_frame, text="选择文件", command=self.load_file)创建一个文本(Text)对象,用来显示分析结果。代码如下:
self.result_text = tk.Text(self.right_frame, height=20)使用pack布局管理器,将组件放在对应的容器中,并指定一些选项,比如side和padx。代码如下:
self.word_length_label.pack(side=tk.LEFT)self.word_length_entry.pack(side=tk.LEFT)...self.top_frame.pack(side=tk.TOP, padx=10, pady=10)...
使用bind方法,将一个事件处理器函数绑定到一个事件上,比如当用户按下回车键时,执行分析词频的函数。代码如下:
self.filepath_entry.bind("", self.analyze)▼资源下载
获取代码及相关资源jieba库,公众号聊天窗口回复python即可
注册会员查看全部内容……
限时特惠本站每日持续更新海量各大内部创业教程,年会员只要98元,全站资源免费下载
点击查看详情
站长微信:9200327
声明:本站为非盈利性赞助网站,本站所有软件来自互联网,版权属原著所有,如有需要请购买正版。如有侵权,敬请来信联系我们,我们立即删除。