如果你对mysql性能调优比较感兴趣,可以观看详细视频合集mysql调优系列
什么是事务日志?
事务要保证ACID的完整性必须依靠事务日志做跟踪,每一个操作在真正写入数据数据库之前,先写入到日志文件中如要删除一行数据会先在日志文件中将此行标记为删除,但是数据库中的数据文件并没有发生变化。只有在(包含多个sql语句)整个事务提交后,再把整个事务中的sql语句批量同步到磁盘上的数据库文件。在事务引擎上的每一次写操作都需要执行两遍如下过程:
先写入日志文件中 写入日志文件中的仅仅是操作过程,而不是操作数据本身,所以速度比写数据库文件速度要快很多。然后再写入数据库文件中 写入数据库文件的操作是重做事务日志中已提交的事务操作的记录。日志组
一般不止设置一个日志文件,一个文件写满之后使用另外一个日志文件提高服务器效率。日志文件的日志同步到磁盘后空间会自动释放,单个日志文件不宜设置过大,如果日志文件过大mysql进程在把日志同步到数据文件的时候可能会崩溃。
事务日志用途
事务日志可以帮助提高事务的效率,使用事务日志,存储引擎在修改表的数据的时候只需要修改其内存拷贝,再把该行为记录到持久在磁盘的事务日志中,而不用每次都将修改的数据本身持久到磁盘。事务日志采用的是追加方式,因此写日志的操作是磁盘上一小块区域的顺序IO,而不像随机IO需要磁盘在多个地方移动。所以采用事务日志的方式相对来说要快的多,事务日志持久后,内存中的修改在后台慢慢的刷回磁盘。期间如果系统发生崩溃,存储引擎在重启的时候依靠事务日志自动恢复这部分被修改数据。
redo log
在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。
在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例:
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块 “粉板”总共就可以记录 4GB 的操作。
redo log包括两部分:一是内存中的日志缓冲(redo log buffer),该部分日志是易失性的;二是磁盘上的重做日志文件(redo log file)日志文件过大,该部分日志是持久的。 在概念上,innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务日志写入到磁盘上的redo log file和undo log file中进行持久化。 为了确保每次日志都能写入到事务日志文件中,在每次将log buffer中的日志写入日志文件的过程中都会调用一次操作系统的fsync操作(fsync函数同步内存中所有已修改的文件数据到储存设备)。因为MariaDB/MySQL是工作在用户空间的,MariaDB/MySQL的log buffer处于用户空间的内存中。要写入到磁盘上的log file中(redo:ib_logfileN文件,undo:share tablespace或.ibd文件),中间还要经过操作系统内核空间的os buffer,调用fsync()的作用就是将OS buffer中的日志刷到磁盘上的log file中。 也就是说,从redo log buffer写日志到磁盘的redo log file中,过程如下:
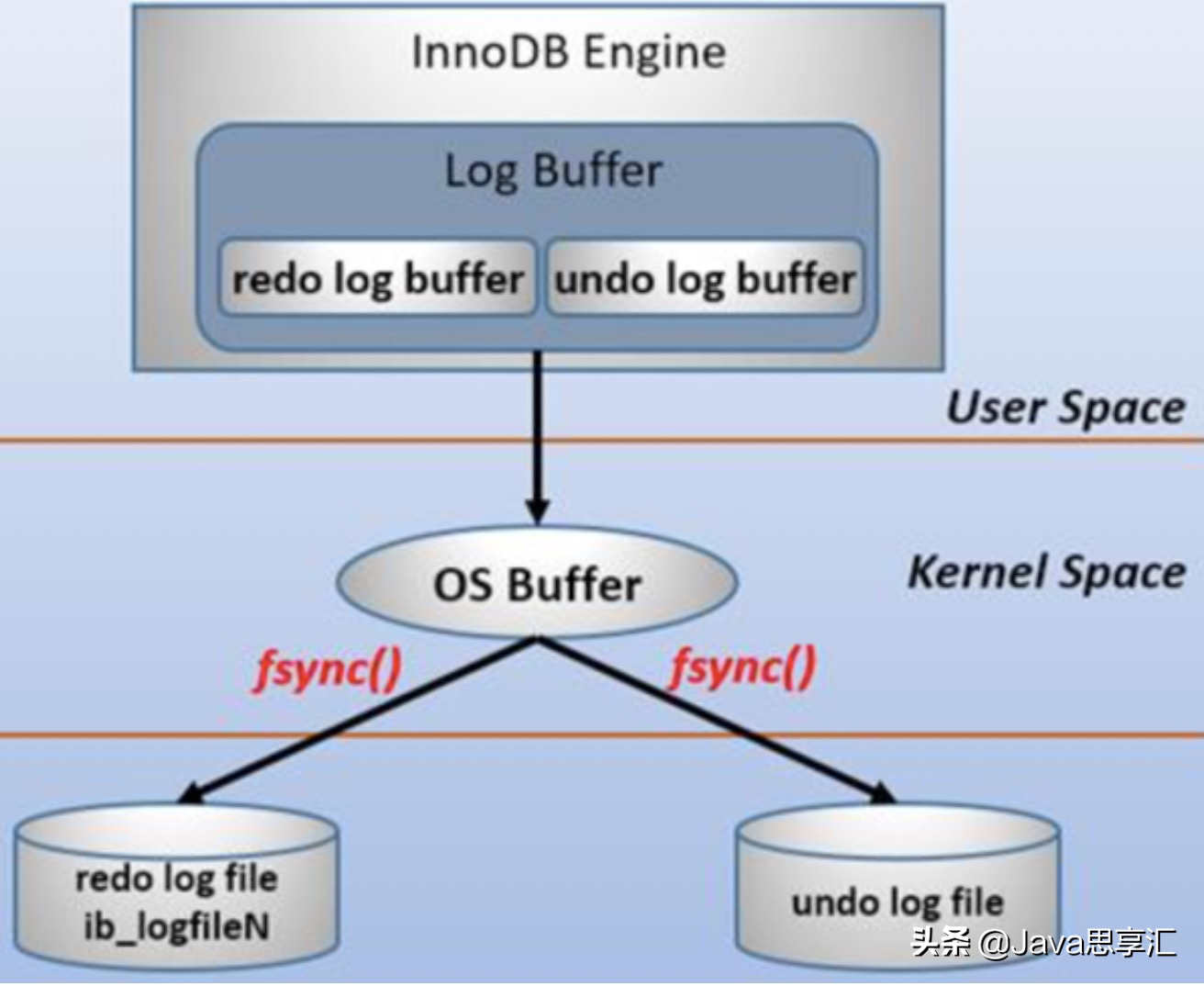
在此处需要注意一点,一般所说的log file并不是磁盘上的物理日志文件,而是操作系统缓存中的log file,官方手册上的意思也是如此(例如:With a value of 2, the contents of the InnoDB log buffer are written to the log file after each transaction commit and the log file is flushed to disk approximately once per second)。但说实话,这不太好理解,既然都称为file了,应该已经属于物理文件了。所以在本文后续内容中都以os buffer或者file system buffer来表示官方手册中所说的Log file,然后log file则表示磁盘上的物理日志文件,即log file on disk。
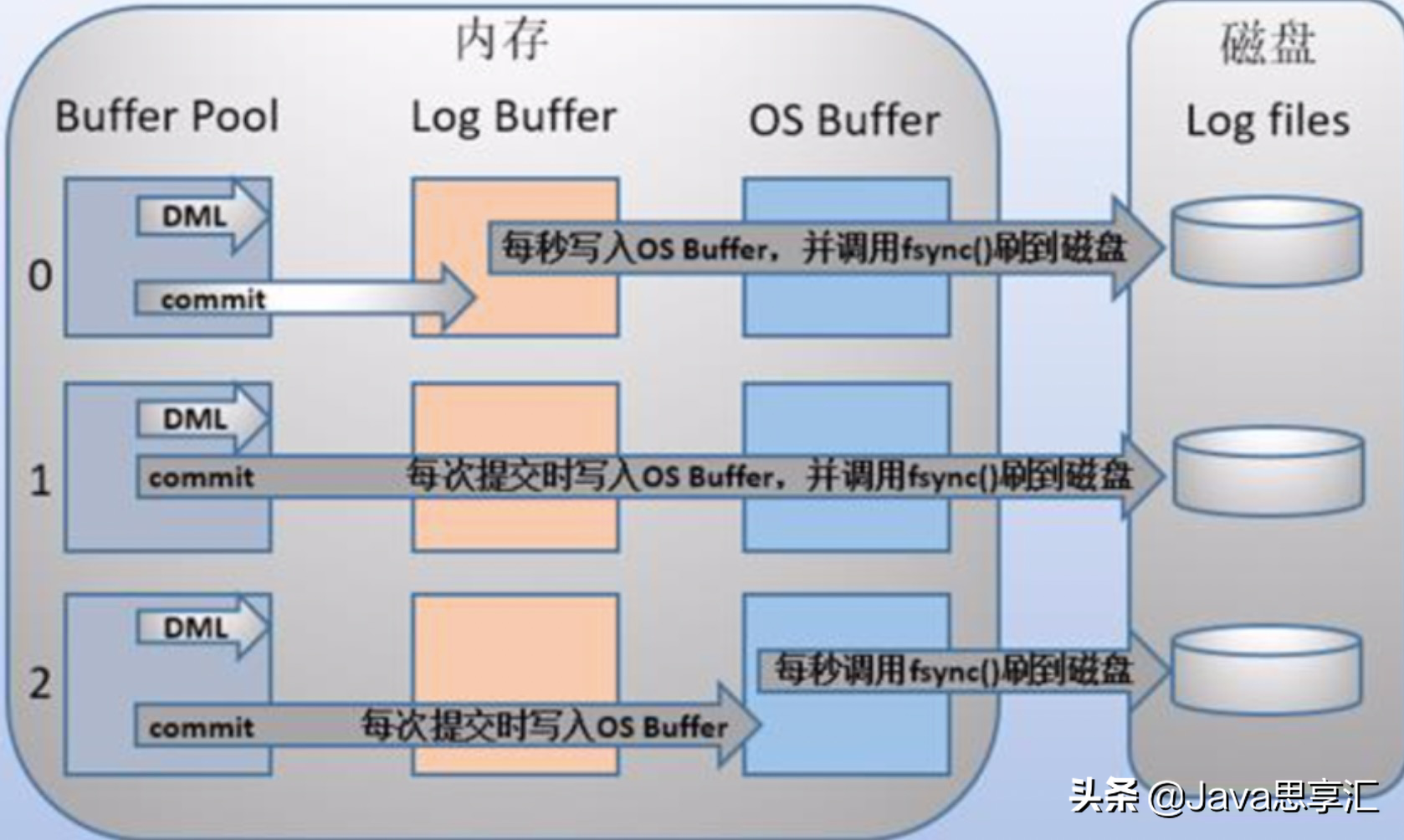
另外,之所以要经过一层os buffer,是因为open日志文件的时候,open没有使用O_DIRECT标志位,该标志位意味着绕过操作系统层的os buffer,IO直写到底层存储设备。不使用该标志位意味着将日志进行缓冲,缓冲到了一定容量,或者显式fsync()才会将缓冲中的刷到存储设备。使用该标志位意味着每次都要发起系统调用。比如写abcde,不使用o_direct将只发起一次系统调用,使用o_object将发起5次系统调用。 MySQL支持用户自定义在commit时如何将log buffer中的日志刷log file中。这种控制通过变量 innodb_flush_log_at_trx_commit 的值来决定。该变量有3种值:0、1、2,默认为1。但注意,这个变量只是控制commit动作是否刷新log buffer到磁盘。
当设置为1的时候,事务每次提交都会将log buffer中的日志写入os buffer并调用fsync()刷到log file on disk中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。当设置为0的时候,事务提交时不会将log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。当设置为2的时候,每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到log file on disk。
注意,有一个变量 innodb_flush_log_at_timeout 的值为1秒,该变量表示的是刷日志的频率,很多人误以为是控制 innodb_flush_log_at_trx_commit 值为0和2时的1秒频率,实际上并非如此。测试时将频率设置为5和设置为1,当 innodb_flush_log_at_trx_commit 设置为0和2的时候性能基本都是不变的。关于这个频率是控制什么的,在后面的”刷日志到磁盘的规则”中会说。 在主从复制结构中,要保证事务的持久性和一致性,需要对日志相关变量设置为如下:
如果启用了二进制日志,则设置sync_binlog=1,即每提交一次事务同步写到磁盘中。总是设置innodb_flush_log_at_trx_commit=1,即每提交一次事务都写到磁盘中。
上述两项变量的设置保证了:每次提交事务都写入二进制日志和事务日志,并在提交时将它们刷新到磁盘中。 选择刷日志的时间会严重影响数据修改时的性能,特别是刷到磁盘的过程。
undo log
undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。
以下是undo+redo事务的简化过程
假设有2个数值,分别为A=1和B=2,然后将A修改为3,B修改为4
start transaction;记录 A=1 到undo log;update A = 3;记录 A=3 到redo log;记录 B=2 到undo log;update B = 4;记录B = 4 到redo log;将redo log刷新到磁盘commit
在1-8步骤的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。
所以,redo log其实保证的是事务的持久性和一致性,而undo log则保证了事务的原子性。undo log是逻辑日志,可以理解为:
binlog
关于mysql主从同步,相信大家都不陌生,随着系统应用访问量逐渐增大,单台数据库读写访问压力也随之增大,当读写访问达到一定瓶颈时,将数据库的读写效率骤然下降,甚至不可用;为了解决此类问题,通常会采用mysql集群,当主库宕机后,集群会自动将一个从库升级为主库,继续对外提供服务;那么主库和从库之间的数据是如何同步的呢?其实就是通过binlog主从同步binlog来实现的。
▪ Binlog是server层的日志,主要做mysql功能层面的事情
▪ 与redo日志的区别:
redo是innodb独有的,binlog是所有引擎都可以使用的。 redo是物理日志,记录的是在某个数据页上做了什么修改,binlog是逻辑日志,记录的是这个语句的原始逻辑。 redo是循环写的,空间会用完,binlog是可以追加写的,不会覆盖之前的日志信息。
Binlog中会记录所有的逻辑,并且采用追加写的方式。一般在企业中数据库会有备份系统,可以定期执行备份,备份的周期可以自己设置。恢复数据的过程:找到最近一次的全量备份数据。 从备份的时间点开始,将备份的binlog取出来,重放到要恢复的那个时刻。主从复制原理
mysql主从复制需要三个线程,master(binlog dump thread)、slave(I/O thread 、SQL thread)。
master
(1)binlog dump线程:当主库中有数据更新时,那么主库就会根据按照设置的binlog格式,将此次更新的事件类型写入到主库的binlog文件中,此时主库会创建log dump线程通知slave有数据更新,当I/O线程请求日志内容时,会将此时的binlog名称和当前更新的位置同时传给slave的I/O线程。
slave
(2)I/O线程:该线程会连接到master,向log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的relay log中,relay log和binlog日志一样也是记录了数据更新的事件,它也是按照递增后缀名的方式,产生多个relay log( host_name-relay-bin.000001)文件,slave会使用一个index文件( host_name-relay-bin.index)来追踪当前正在使用的relay log文件。
(3)SQL线程:该线程检测到relay log有更新后,会读取并在本地做redo操作,将发生在主库的事件在本地重新执行一遍,来保证主从数据同步。此外,如果一个relay log文件中的全部事件都执行完毕,那么SQL线程会自动将该relay log 文件删除掉。
下面是整个复制过程的原理图:
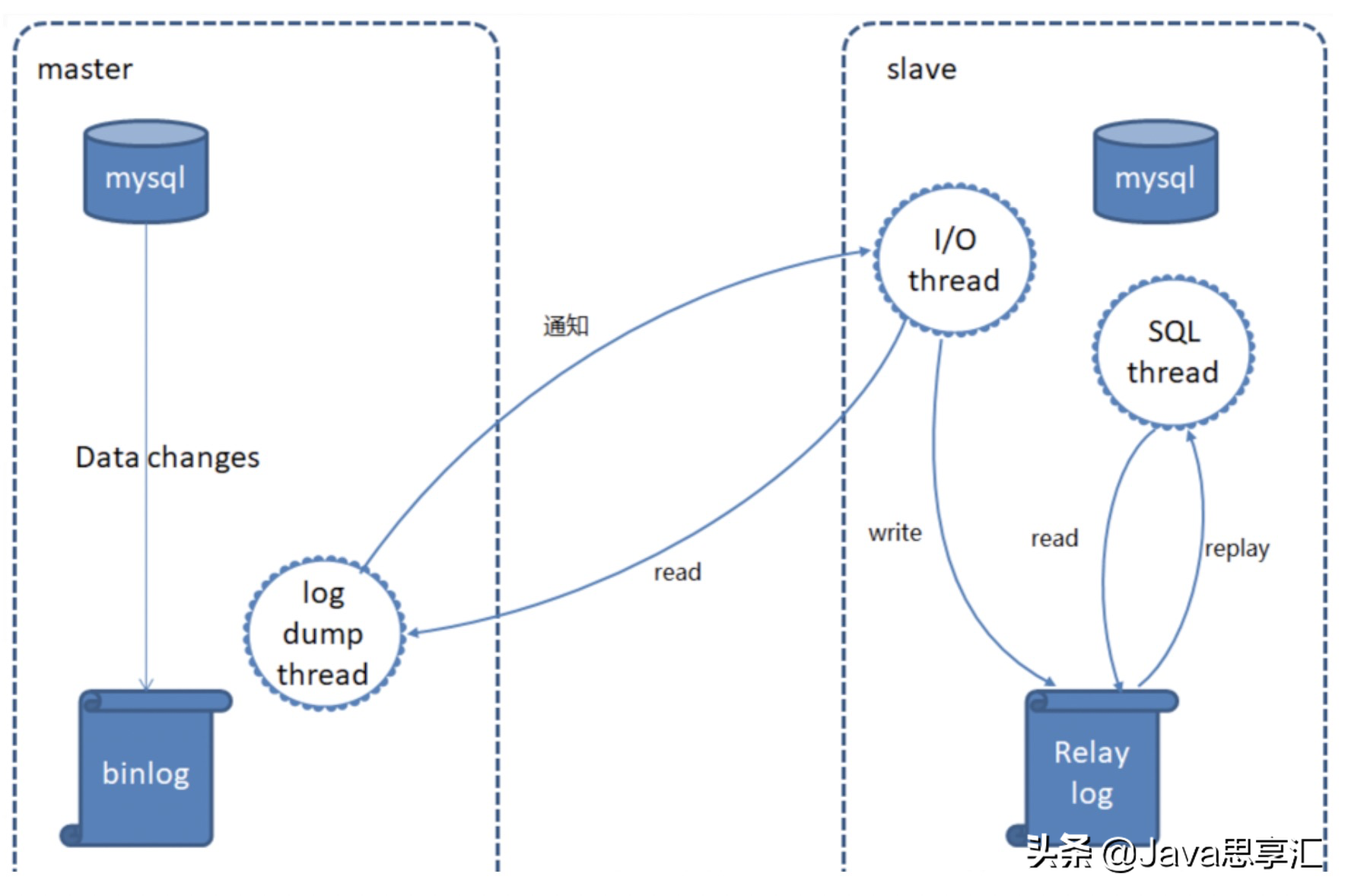
主从复制过程
不断分享开发过程用到的技术和面试经常被问到的问题日志文件过大,如果您也对IT技术比较感兴趣可以「关注」我
注册会员查看全部内容……
限时特惠本站每日持续更新海量各大内部创业教程,年会员只要98元,全站资源免费下载
点击查看详情
站长微信:9200327