最新声音3秒极速克隆,最适合新手的版本,从此声音自由。
近日,阿里通义实验室发布开源语音大模型项目FunAudioLLM,而且一次包含两个模型:SenseVoice和CosyVoice。
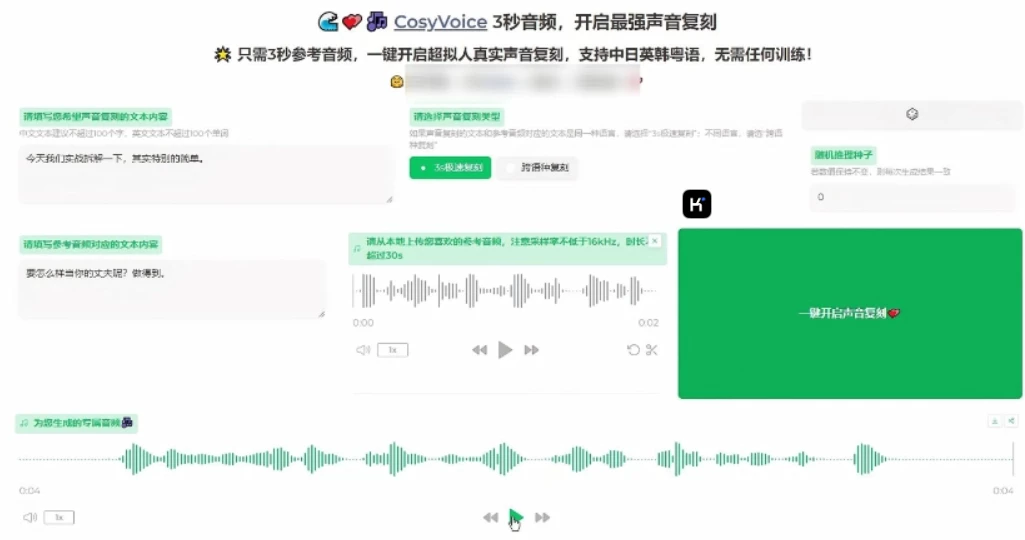
CosyVoice专注自然语音生成,支持多语言、音色和情感控制,支持中英日粤韩5种语言的生成,效果显著优于传统语音生成模型。
仅需要3~10s的原始音频,CosyVoice即可生成模拟音色,甚至包括韵律、情感等细节,包括跨语种语音生成。
而且CosyVoice支持以富文本或自然语言的形式,对生成语音的情感、韵律进行细粒度的控制,生音频在情感表现力上得到明显提升。
研究团队提供了基模型CosyVoice-300M、经过SFT微调后的模型CosyVoice-300M-SFT、以及支持细粒度控制的模型CosyVoice-300M-Instruct,可满足不同场景下的使用需求。CosyVoice-300M本身具备一定从文本内容中推断情感的能力,经过细粒度控制训练的模型CosyVoice-300M-Instruct在情感分类中的得分更高,具备更强的情感控制能力。
CosyVoice很好地建模了合成文本中的语义信息,达到了与人类发音人相当的水平。此外,通过对合成音频进行重打分,能够进一步降低识别的错误率,甚至在内容一致性和说话人相似度上超越人类。
作者:无言以对2012 https://www.bilibili.com/read/cv35975908/?jump_opus=1 出处:bilibili
工具地址:
声明:本站为非盈利性赞助网站,本站所有软件来自互联网,版权属原著所有,如有需要请购买正版。如有侵权,敬请来信联系我们,我们立即删除。