作者:jiaqiangwang,腾讯 IEG 后台开发工程师
背景
在大数据及机器学习日益火爆的今天,数据作为基石发挥了至关重要的作用。网页内容爬取作为数据的一个重要补充来源,数据爬取开发成了一个必不可少的工作。
在业界,普遍的做法是采用 scrapy 等框架不断进行 case by case 的爬取代码编写,这种做法在需求量逐渐增大后会出现大量重复工作、大量针对某个网站或需求开发的特殊逻辑等,导致技术不能持续积累沉淀、开发耗时长、维护压力越来越大。
我们在调研了业界最新动态后,决定开发一款轻量级的可视化定向数据爬取工具来解决上述问题。我们将它命名 bodhi,中文名:菩提,寓意在“菩提本无数(据)”。
本文只是提供一种思路、一种工具,使用者自身需要合规使用。
同类工具一览
在数据爬取领域,可供选择的工具非常多,比如以 scrapy 为代表的开源工具包、以 portia、八爪鱼为代表的可视化数据爬取工具;
下面我们从是否需要使用者有技术背景、是否支持动态网页、是否免费、是否开源、是否能够灵活支持需求、是否轻量级应用几个方面对上面列举的工具进行对比。
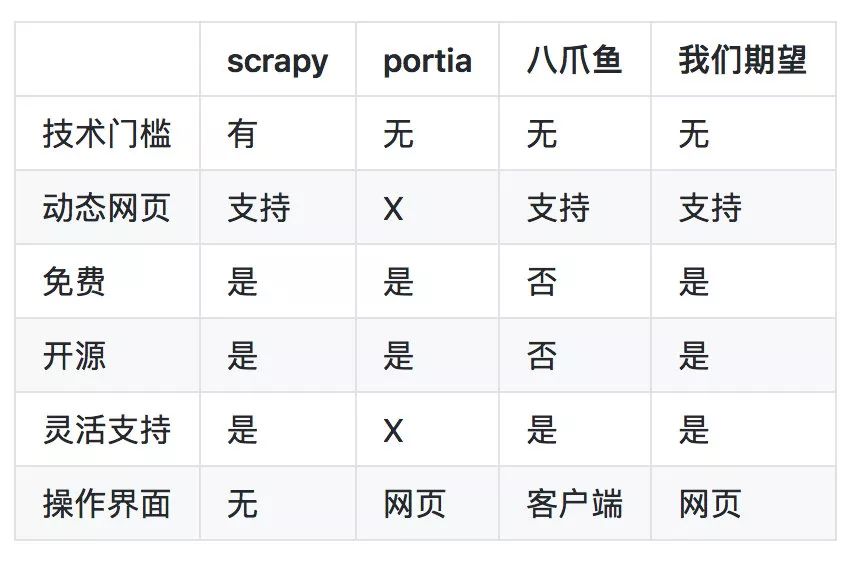
注:以上对比基于当前最新版本,其中,scrapy 1.74, portia 2.08, 八爪鱼 8.0。
scrapy 是一个非常优秀的开源框架,但是需要编码,使用技术门槛较高,跟我们的初衷不符;
portia 是应该是第一个开源的可视化 web 数据爬取工具,想法非常好,但是仅支持静态网页,没有对动态网页提供支持,在几乎全是动态网页的今天明显不能完成大多数页面的提取;
八爪鱼是国内使用量最大的商业数据爬取工具之一,提供客户端,其免费版无法做到大规模、7*24 小时的持续爬取,无法满足工业化应用;
为了更快更好的支撑业务上不断增长的需求,我们期望有一个适配性很广,能够大规模不间断爬取数据的工具帮我们解决工作中遇到的问题。2018 年底,在公司内外没有找到一个可以充分满足需求的数据爬取工具的情况下,我们在充分调研了 portia 和八爪鱼后,期望能够自研一款可以支持浏览器即开即用的、低技术门槛、能够支持绝大多数需求、成熟后能够开源的可视化网页数据爬取工具。
技术选型
我们明确了目标:轻量、低门槛、通用性强的网页数据爬取工具。
轻量:我们抛弃客户端,采用网页来实现即开即用;将功能边界限定到只做网页文字的下载功能,放弃不必要的周边功能使其更加简洁;
低门槛:尽量模拟人们在浏览网页时的使用习惯完成配置,做到产品同学可以自行完成需求开发;
通用性强:采用无头浏览器模拟 web 浏览器,整体上比 http 请求更通用。
bodhi 工具简介
bodhi(菩提)是一款可视化的数据爬取工具,力求让用户通过模拟日常浏览网页习惯就可以在网页上提取自己所需要的数据。
人类在上网时主要通过鼠标的点击、滚动以及键盘的输入来完成页面浏览,大家已经习惯这种使用方式,我们在这基础上进行抽象总结,除了提供基础的点击、滚动、输入动作,还提供了更高级的选择相似元素、提取内容、翻页等操作方便用户更加便捷的完成任务配置;
bodhi 采用流程图模式,大多数情况下,用户不需要对流程图进行直接操作网页数据爬取工具,流程图更多的是作为一个可视化的配置,用户可以通过可视化的点选网页上的元素来完成后续操作,完全符合人工浏览网页的思维习惯。
这里通过一些关键词介绍一下 bodhi,具体的技术细节由于篇幅有限这里不会展开。
嵌入式页面
我们采用 B/S 架构,需要在我们的页面内嵌欲爬取的页面,这里我们并没有采用 iframe 直接嵌入页面,因为这样做,一方面有些网站不能直接通过 iframe 打开,另一方面如果使用 iframe,用户在 iframe 中进行点击(比如打开另一个网页)、输入会产生不可控的行为。
我们采用在后台通过无头浏览器模拟用户打开的浏览器,可以把它理解为一个“傀儡”,这个“傀儡”根据用户发送的 URL 打开网页,并监听网页变化,将二次加工后的网页内容实时增量同步到前端进行展示。用户后续仍然可以继续发送点击、输入等动作指令,操控“傀儡”所打开的网页。
下图红框部分为采用上述方式打开的一个网页。
灵活选取
例如我想要选择下图中的所有具体游戏,而非游戏类型(单机游戏)或具体站点(爱玩),就可以得到下图所示的图例,其中红色及蓝色代表已经选中的内容。
bodhi可以通过让用户不断的选择、反选操作来最终确认需要爬取的内容。
智能提取
大多数网页都是一篇文章,而这些文章的排版又不尽相同,如果通过适配不同的文章模板来提取内容,必将导致工作量大增,所以有必要提供一个相对智能的网页内容提取组件完成这个工作。
下图红框部分,bodhi 通过一个“文章识别”组件可以快速提取文章内容。
循环翻页
一般网页都存在翻页的 case,对于存在“下一页”的情况,我们可以通过不断点击“下一页”完成所有内容的遍历,但是对于没有“下一页”按钮的情况就会比较复杂,所以我们做了一个循环翻页功能,可以应对所有翻页的情况。
比如下图的情况,只提供了“最后一页”按钮,在翻页过程中,会不断有新的页码出现,如果没有智能翻页功能将会非常痛苦。

调试
为了保证用户在配置及后续维护过程中知道到底做了什么,存在什么问题,我们也做了一个简版的调试功能网页数据爬取工具,帮助用户方便调试。下图红框部分为调试界面。
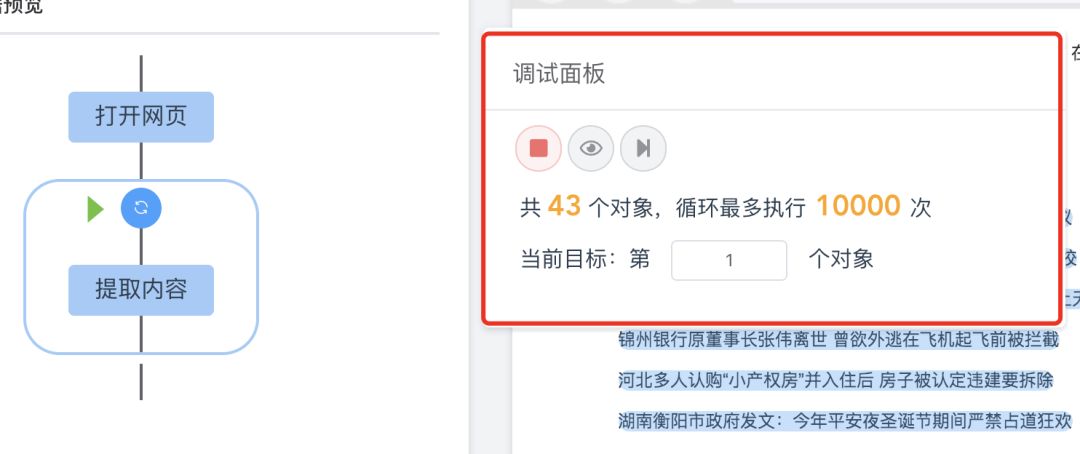
分布式部署
采用无头浏览器的一个弊端就是爬取效率相对低下,为了保障爬取效率,bodhi 一方面进行了基于腾讯云的分布式部署,同时在单机上也对单爬取任务进行并行切分来实现加速。
robots 协议支持
robots 协议作为网站与爬虫之间的君子协议,用于保证网站的隐私等信息。我们也支持在后台做数据爬取时遵守 robots 协议,让 bodhi 成为一个文明、君子的工具。
存在问题及后续规划
当然,我们的 bodhi 并非完美,最多算是一个刚刚及格的工具,有很多待完善的地方,比如我们天然不支持页面嵌入 iframe 内容的爬取、操作流畅度上有很大提升空间等,这些都是我们后续需要继续努力完善的。
我们也希望更多的人能够使用它提高工作效率,更多对数据爬取技术感兴趣的人可以一起开发、完善 bodhi,打造一个更强大的数据爬取工具!
注册会员查看全部内容……
限时特惠本站每日持续更新海量各大内部创业教程,年会员只要98元,全站资源免费下载
点击查看详情
站长微信:9200327



